Why MobileLLM Made Me Question the ‘Bigger is Better’ AI Mindset?
Breaking The "Bigger Is Better" Myth
Sohom Pal
AI-ML Engineer (Z-III), Founder-in-Residence, Zemuria Inc.

We’ve been in a parameter arms race for a while now—every new model is measured by how many
billions or even trillions of parameters it has. And sure, for many tasks, having more parameters
means more nuance, better understanding, and more contextual awareness. But
this
paper hammers home that bigger isn’t always smarter, especially if you’re aiming for efficiency.
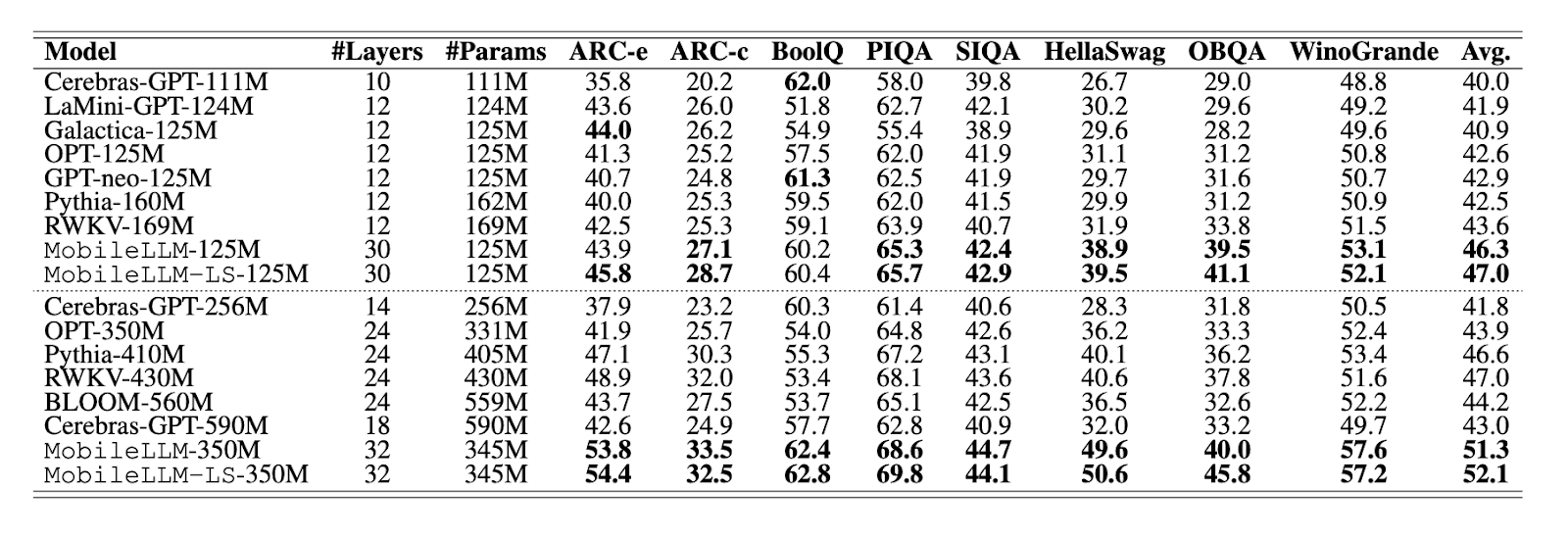
With MobileLLM, they’re essentially saying, “We don’t need a ton of parameters if we build our models smarter.” Instead of brute-forcing size, they optimize the architecture to extract more intelligence from fewer parameters.
And this makes me wonder: Have we been too fixated on model size and not enough on how we’re designing these models?
It opens up many new possibilities when we start thinking about LLMs in terms of depth and efficiency rather than just parameter count. We could use these models in low-power devices, offline applications,
or embedded systems where traditional large models just don’t fit.

Depth Vs. Width: Which Matters More?
One of the more interesting findings from MobileLLM is how it challenges the idea that
“more parameters = better performance.” They argue that, for smaller models,
depth (more layers) is more important than width (wider layers). This flies in the face of conventional thinking, which usually focuses on making models wider to pack in more parameters.
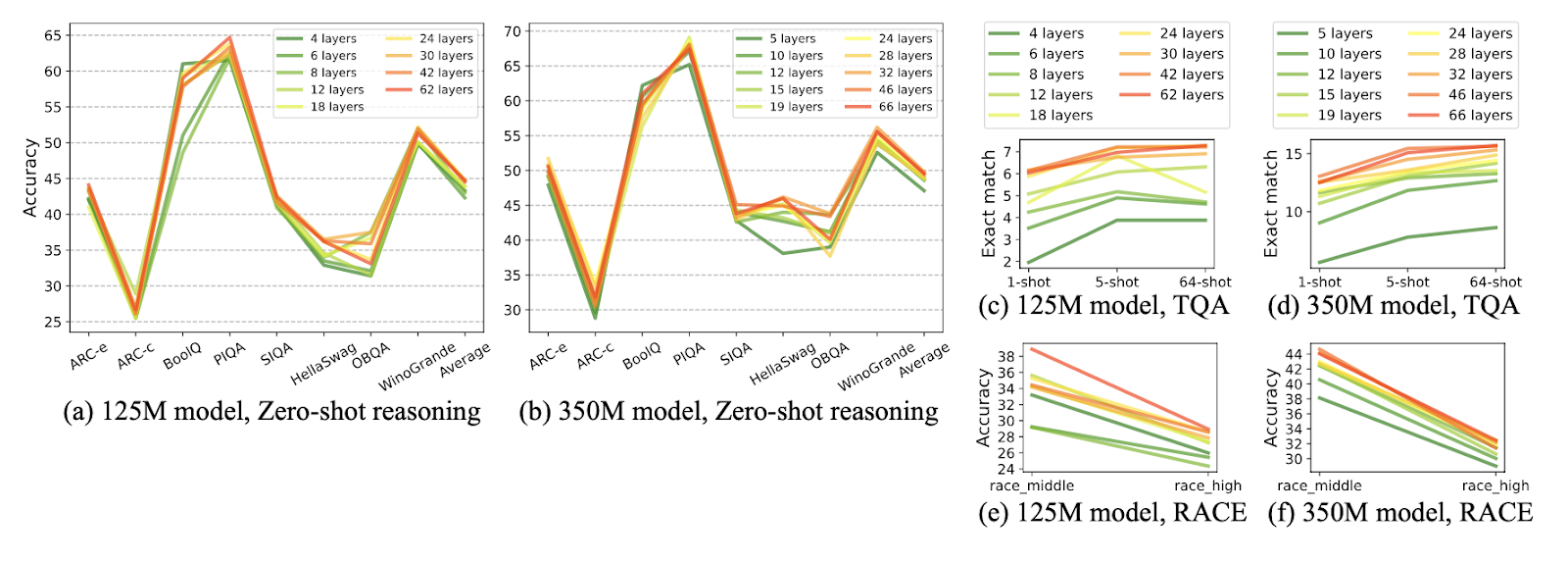
MobileLLM shows that deep-and-thin architectures do a better job of capturing complex patterns with fewer parameters. That’s a massive shift in thinking. Instead of making models fatter and more resource-hungry, we can focus on
making them more profound and efficient, unlocking the potential for smaller, more agile models.
This raises a bigger question: Have we been focusing too much on scaling models in width rather than
refining their architecture? MobileLLM makes a strong case that focusing on depth is the more intelligent move for smaller models.
Inference Speed
Another big challenge for deploying large models on mobile is inference speed. Cloud-based models can rely
on clusters of GPUs to handle inference quickly, but on-device models don’t have that luxury. MobileLLM is making a clever move here by focusing on weight-sharing techniques
like block-wise weight sharing, which allows them to deepen models without slowing them down significantly.

This is important because, for real-time applications like voice assistants or translation, even minor delays in response time can
be super noticeable. What MobileLLM is doing, by keeping models small but fast, is laying the groundwork for real-time AI
on devices without needing to connect to the cloud.
Can This Approach Be Generalized Across Other Real-Time, Low-Latency Tasks?
I think so. This architecture could easily be adapted for things like augmented reality, gaming AI, or edge computing, where every millisecond counts.
Democratizing LLMs: A New Wave?
One thing that excites me most about MobileLLM is the idea that it could help democratize access to powerful AI. To run a cutting-edge
language model, you need either a cloud server (which costs money) or a powerful local machine (which isn’t cheap). Neither option is accessible to everyday users, small developers, or people in regions with limited connectivity.
However, optimizing models like MobileLLM to run on mobile devices efficiently opens up a new world of possibilities. Imagine people in remote areas having access to
AI-powered tutors or small startups can deploy smart apps without expensive infrastructure.
That’s pretty revolutionary.
How long until we see more companies focusing on optimizing smaller, on-device models
rather than just chasing bigger, cloud-based solutions? This could begin a shift in how we think about AI deployment.
Energy Consumption: The Hidden Challenge
Now let’s talk about something that doesn’t get as much attention: Energy consumption. Running large AI models
locally on devices can drain batteries fast. MobileLLM takes this challenge head-on by optimizing energy per token—ensuring that their models are fast and energy-efficient.
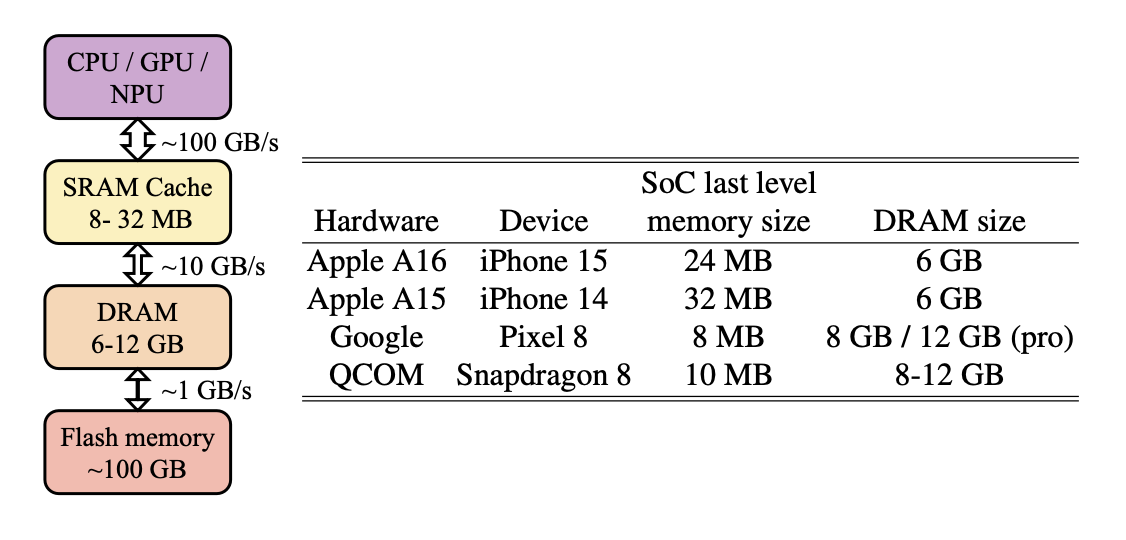
For instance, they point out that a typical 7B model could drain your phone’s battery in under
two hours at ten tokens per second. Meanwhile, MobileLLM’s 350M model can run daily on a single charge. That’s a game-changer for ensuring AI-powered apps don’t become battery killers.
This raises another question: Will energy-efficient AI become the new standard? Considering wearables,
IoT devices, and even autonomous systems, energy efficiency will be crucial for making these technologies viable in the long run.
Trade-Offs: Are Smaller Models Enough?
Of course, one of the things we need to consider is what we lose by going smaller. MobileLLM performs well
in tasks like API calls and essential chat functions, but what about more complex tasks that require deeper reasoning or multi-step problem-solving?
Before sacrificing accuracy or capabilities, is there a ceiling to how small we can go?
This trade-off is going to be critical as we move forward. MobileLLM does a great job of showing
how much you can accomplish with a sub-billion model, but how far can this be pushed before we start seeing diminishing returns?
The Future Of On-Device AI
To sum it all up, MobileLLM is paving the way for a future where LLMs don’t just live in the cloud—they live right in our pockets. It’s a huge leap in terms of
making AI more accessible, faster, and more energy-efficient for mobile and embedded devices.
The big questions moving forward are:
- How much further can we push the limits of small models?
- Will more companies follow this path, optimizing for smaller, more efficient models instead of chasing size?
- How do we balance the trade-offs between model size, performance, and energy consumption?
I think MobileLLM is showing us that the future of AI isn’t just about making models bigger—it’s about making them smarter, faster, and more adaptable for the everyday devices we use.